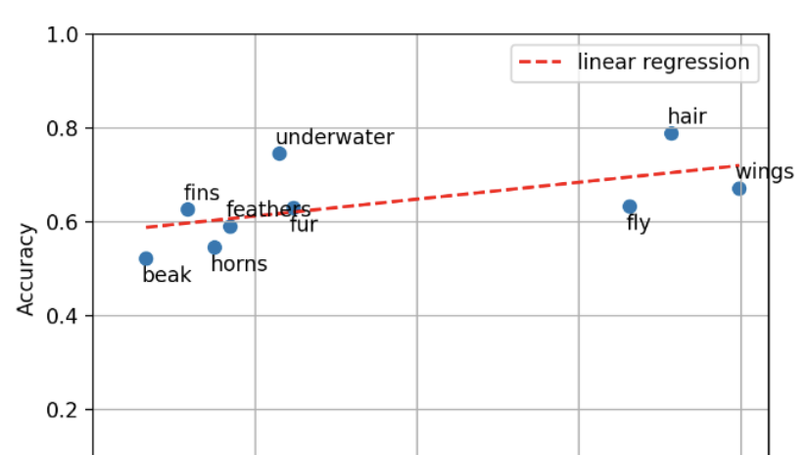
Pre-trained language models (LMs) have recently demonstrated outstanding results across a variety of tasks. However, it remains unclear precisely what knowledge the LM manages to capture during pre-training and how word frequency in the training corpus affects the acquisition of knowledge about these words.