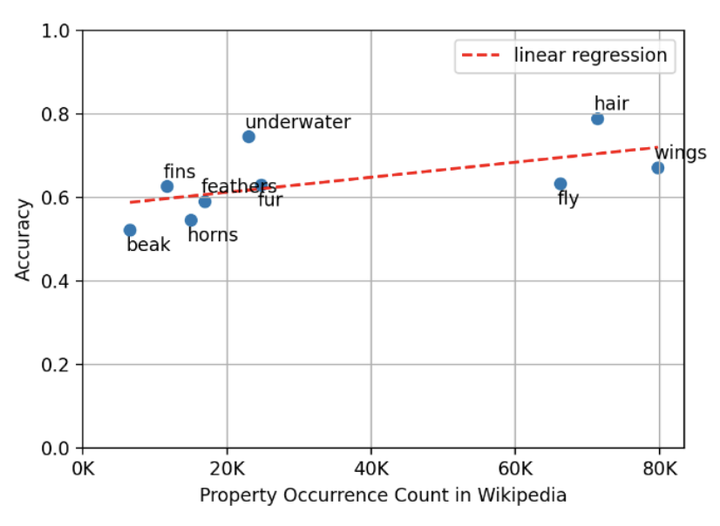
Pre-trained language models (LMs) have recently demonstrated outstanding results across a variety of tasks. However, it remains unclear precisely what knowledge the LM manages to capture during pre-training and how word frequency in the training corpus affects the acquisition of knowledge about these words.
As part of the final project of NLP course I explored the correlation between word occurrence in the language and general world knowledge acquired by a Language Model during pre-training. In my work I propose a framework for testing this subject, using a downstream “Yes/No” QA task. My findings show positive correlations between: (a) word occurrence and the accuracy of answers for this word. (b) co-occurrence of two words and a tendency of the model to answer “Yes” for questions about their relation.